[导读]:1-3行:注释; 第4行:允许所有页面被抓取; 4-6行:禁止搜索引擎抓取的页面 7-8行:禁止搜索引擎爬行data文件夹,允许搜索引擎抓取data文件夹下的upload文件夹里的页面; 9-10行...
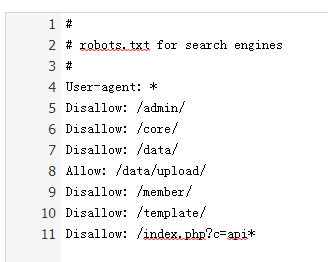
1-3行:注释;
第4行:允许所有页面被抓取;
4-6行:禁止搜索引擎抓取的页面
7-8行:禁止搜索引擎爬行data文件夹,允许搜索引擎抓取data文件夹下的upload文件夹里的页面;
9-10行:禁止搜索引擎爬行的页面。
第11行:禁止搜索引擎爬行首页api*(*代表0-n个任意字符)
###所有该文件目录下的网页
allow可以允许抓取disallow下的文件,第7和第8不冲突
###第7和第8 是不是冲突, 按照我的理解第8行 应该是没用 先执行屏蔽data 然后你又让他去抓data下的upload,这执行不过去吧。
###为什么要屏蔽 让他抓就是 抓取的越多不越好
###user-agent=*意思允许所有搜索引擎蜘蛛爬取
disallow:/文件名 意思不允许蜘蛛爬取该文件下内容
allow:/文件名 意思允许蜘蛛爬取该文件下内容 然后你自己对应着看吧
据说叫搜索引擎协议
###据说叫搜索引擎协议
###这个不太会看,据说叫搜索引擎协议
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/101496.html