[导读]:www点benpaoba点com站点 用光年软件处理 出来的数据表结果 早就已经进行robots.txt禁止抓去了 只抓取,不索引? ### 搜索引擎的Robots规则比较正统的解释:(善用搜索) robots.txt协议...
www点benpaoba点com站点
用光年软件处理 出来的数据表结果
早就已经进行robots.txt禁止抓去了
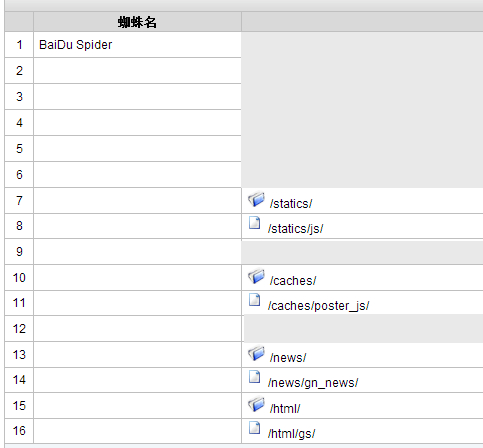
只抓取,不索引?
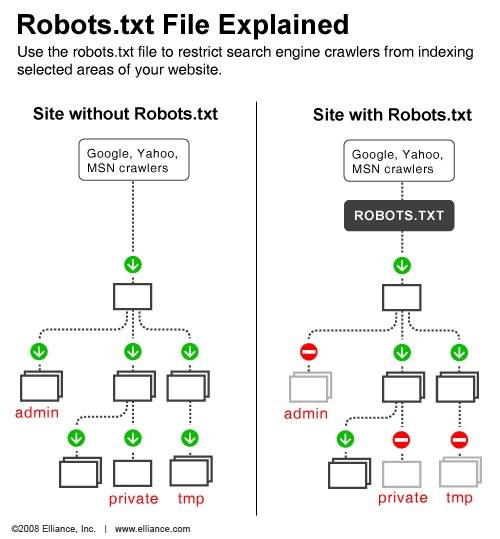
###搜索引擎的Robots规则比较正统的解释:(善用搜索)
robots.txt协议并不是一个规范,而只是约定俗成的,通常搜索引擎会识别这个文件,但也有一些特殊情况。
对于Google来说,使用robots也未必能阻止Google将网址编入索引,如果有其他网站链接到该网页的话,Google依然有可能会对其进行索引。按照Google的说法,要想彻底阻止网页的内容在Google网页索引中(即使有其他网站链接到该网页)出现,需要使用noindex元标记或x-robots-tag。例如将下面的一行加入到网页的header部分。
如果Google看到某一页上有noindex的元标记,就会将此页从Google的搜索结果中完全丢弃,而不管是否还有其他页链接到此页。
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/22523.html