1、蜘蛛停留时间是怎么计算的?
总停留时间,即蜘蛛下载该网站页面的时间总和
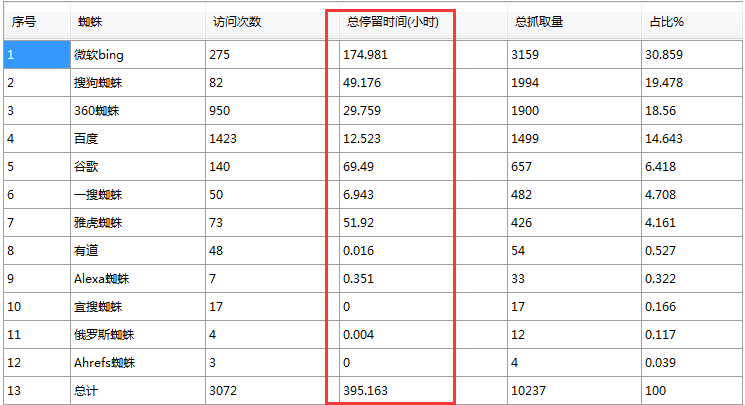
如百度,来了1423只蜘蛛,共下载1499个页面,用时。平均下载一个页面的时间为?
2、影响蜘蛛停留时间的因素会有哪些?
站点质量
页面大小
服务器带宽
抓取策略
抓取压力控制
......是否还有其他原因?
网站的打开速度是否会影响蜘蛛停留时间?
会
服务器带宽、页面大小、图片、JS等都会影响蜘蛛的下载时间。
3、蜘蛛停留时间的长短能够代表什么?
停留时间长:蜘蛛多/页面体积大/服务器带宽低/站点质量高
停留时间短:蜘蛛少/页面体积小慢/服务器带宽高/站点质量低
最近一直在看爬虫这方面的书籍,就了解这么一点点东西,可能还不是很完善,希望指出。
1、我们自己做的也有日志统计工具,蜘蛛停留时间是蜘蛛每次请求的所有网页时间的总和,也可以说是网页的加载速度。这个对研发工作也有很大的帮助。公式可以这样算,蜘蛛停留时间=网页总数X网页平均加载速度
2、和页面信息质量没有直接关系。网站的打开速度直接影响蜘蛛停留时间。
3、停留时间长,说明在你这里停的时间长,说明在你网站抓取页面所用的时间长,可能是抓取你的页面数量大,也有可能是抓取你的页面耗费的时间长。
关于蜘蛛页面停留时间长,一般是因为抓取网站的网页量比较大,如果抓取量大,一般能够说明网页质量不错,网页质量不错,一般能够说明网站质量不错。如果抓取量大,那么被收录和索引的概率就大,参与排名的几率就大。
所以,我们都在想办法提高蜘蛛的停留时间,更准确的说是在想办法提高蜘蛛的抓取量。
1、如果日志是一天的统计量,那蜘蛛总停留的时间应该是访问次数*每次停留时间(总抓取量),不可能在一个页面停留12小时吧!!囧~~
2、你所说的页面信息量,还有链接的数量,链接数越多,访问越多,总停留时间也就越长。
3、停留时间长短应该跟页面的内容质量有关,蜘蛛初步判断该页面网上到处都有相同内容,价值不大,走人。网站的链接结构应该也有关系,还有一点是根据服务器的情况调整抓取频率,避免对网站造成亚历山大(站长工具有说明)。
以上纯属个人虚构,对日志的研究力度还不够。。。
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/32664.html