[导读]:前几天看了一个人写的文章,提到这个问题,我看有点道理 ### 百度Robots协议有个生效期,反应可能没这么快。 ### 在Robots.txt中,加:号,后面必有一个空格,和值相区分开。你...
前几天看了一个人写的文章,提到这个问题,我看有点道理
###百度Robots协议有个生效期,反应可能没这么快。
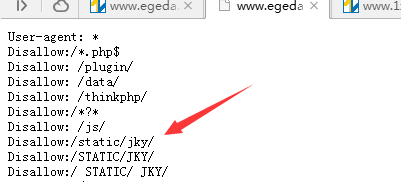
###在Robots.txt中,加:号,后面必有一个空格,和值相区分开。你去百度的站长工具哪里检查一下,如果robots写正确了。那就不会抓取你的文件。如果不会写可以生成一个,或者在一个相对应的网站复制一个看看别人是怎么写的,
###Disallow:/static/jky
###如果是页面调用了,那么搜索引擎还是有可能会抓取的,他会识别这个页面是否有质量,然后决定是否收录。
###百度是这样子的,它不会严格遵守规刚,人不都说百度是流氓吗?对于流氓有什么不好理解的行为,我的站也是。淡定。
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/33012.html