喜欢自己用手机K歌?但K歌App里人声往往清除得不够干净,录制起来效果一般。
现在有个AI神器可以干净地剥离歌曲里的乐器声啦。

来自法国的音乐流媒体公司Deezer开源了一个音轨分离软件spleeter,只需输入一段命令就可以将音乐的人声和各种乐器声分离,支持mp3、wav、ogg等常见音频格式。
这款软件基于TensorFlow开发,效果拔群,有网友说自己曾经试过无数类似软件,spleeter是最好用的一个。
量子位尝试了周杰伦的新歌《说好不哭》,人声轨道在开头部分几乎实现了静音,听不到任何乐器声,直到26秒才开始出现周杰伦的歌声:
而伴奏部分在整个过程中仅有极少量微弱的换气声:
spleeter还支持GPU加速。如果在GPU上运行,会比实时分解速度快100倍,也就是说分解一首5分钟的歌曲只需要3秒。
spleeter在GitHub上线仅仅一周,就收获了2.4K星,在Hacker News上也有1000+的热度。
最多分离5个音轨
用户可以根据自己的需求来训练模型,Deezer还给出了在musdb数据集上的预训练模型,因此能直接拿来使用。
在官方提供的预训练模型里,spleeter可将人声和乐器声分为2个音轨,已经能满足基本的要求。
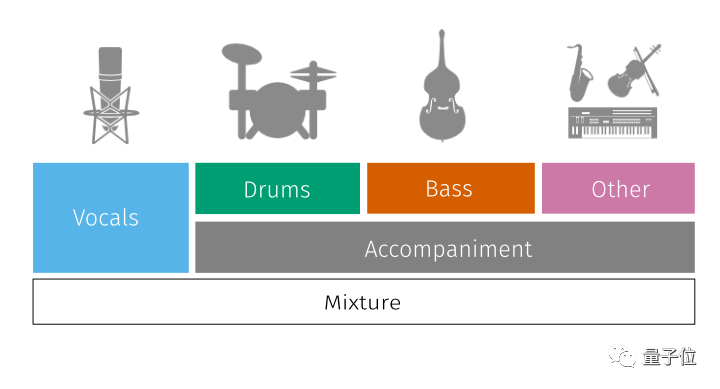
此外它还能把乐器声进一步分离为鼓、贝斯、钢琴及其他乐曲,加上人声,spleeter最多可以分离出5个音轨。
其中,2个音轨和4个音轨的模型在musdb据集上均具有最先进的性能。
使用方法
spleeter可以从conda或者pip安装。
如果用conda安装,可以选择CPU或者GPU环境,以CPU环境为例:
git clone https://github.com/deezer/spleeter
conda env create -f spleeter/conda/spleeter-cpu.yaml
conda activate spleeter-cpu
如果想换成GPU环境,只需将上述代码中的spleeter-cpu换成spleeter-gpu。
在分离音轨的命令中,加入选项-p spleeter:4stems来指定音轨数量,如果不加,系统默认分离为2个音轨。
spleeter separate -i audio_example.mp3 -o audio_output -p spleeter:4stems
最终乐器和人声将以wav文件的格式保存在audio_output文件夹中。
分离过程可以在GPU或CPU上执行。在GPU上运行,速度非常快,可以实现100倍的加速。
经过实测,在单个英伟达 GTX 1080上,spleeter只用了90秒就分解完了3小时27分钟长度的musDB测试数据。
pip安装更简单,但是不支持GPU加速,一般分解一两首歌已足够使用:
pip install spleeter
---------------------------------------------------
来自法国的音乐流媒体公司Deezer开源了一个音轨分离软件spleeter,只需输入一段命令就可以将音乐的人声和各种乐器声分离,支持mp3、wav、ogg等常见音频格式。
这款软件基于TensorFlow开发,效果拔群,有网友说自己曾经试过无数类似软件,spleeter是最好用的一个。
如果在GPU上运行,会比实时分解速度快100倍,也就是说分解一首5分钟的歌曲只需要3秒。
spleeter在GitHub上线仅仅一周,就收获了2.4K星,在Hacker News上也有1000+的热度。
最多分离5个音轨,用户可以根据自己的需求来训练模型,Deezer还给出了在musdb数据集上的预训练模型,因此能直接拿来使用。在官方提供的预训练模型里,spleeter可将人声和乐器声分为2个音轨,4个音轨,钢琴、架子鼓等5个音轨。
时间2020.2.14
开始
一、windows下(官方建议使用linux):
1.下载anaconda:
打开清华anaconda源:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
这里下载Anaconda3-5.2.0-Windows-x86_64.exe
注意太新的python版本会不兼容
2.安装anaconda
双击安装,此处没啥好说的,注意勾选上环境变量那一个(勾上会变红)
3.更换anaconda为清华源
在cmd命令行输入下面代码后回车:
conda config --set show_channel_urls yes
1
然后找到c盘/你自己的电脑名的文件夹,里面有个.condarc
在这里插入图片描述
用记事本打开,把里面的内容全部替换成下面网址里黑色部分,并保存退出:
https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
在这里插入图片描述
4.创建初始环境
开始菜单里打开Anaconda Navigator图形界面,选择Environment环境,选择新建Creat,命名为music,勾选python3.6,确定,等待下载初始环境完成。
5.激活anaconda里新建的music基础环境
开始菜单打开Anaconda prompt(或cmd命令行),输入下面代码后回车:
activate music
1
进入如下界面:
在这里插入图片描述
6.安装spleeter环境
接着步骤5键入下面代码后回车:
conda install -c conda-forge spleeter
1
等待提示,输入y后回车
等待下载环境完成。
7.下载已训练好的模型(以分离人声音乐为例,还可以下载更高品质的模型)
进入以下网址,下载 2stems.tar.gz
https://github.com/deezer/spleeter/releases
如果下载慢可以看我主页CSDN上传的文件
解压到如下目录下C:\Users\ef\pretrained_models\2stems
(在pretrained_models的上一级目录运行)
在这里插入图片描述
在这里插入图片描述
8.要分离的音乐目录:
我放在D:/code/test.mp3
9.运行(首先进入music环境,若已关掉重复5即可打开)
在这里插入图片描述
接着键入下面代码后回车(注意文件目录)
python -m spleeter separate -i D:/code/test.mp3 -p spleeter:2stems -o output
1
(此处可能出现无法创建文件的bug,删掉output里面的文件重复运行1次即可)
在这里插入图片描述
在output里可以查看分离的文件
在这里插入图片描述
二、ubuntu18.04 (linux)下
此处仅介绍安装使用
显卡驱动、cuda和cudnn的安装参考下面这个帖子
https://blog.csdn.net/qq_27139123/article/details/99686086
1.下载Anaconda3-5.2.0-Linux-x86_64.sh:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
安装:找到下载后的页面打开终端输入:
sudo sh Anaconda3-5.2.0-Linux-x86_64.sh
1
2.换anaconda为清华源(下载比较快)
清华源:https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
在根目录下修改.condarc换清华源:
//终端键入后回车,并全部替换为下面的清华源镜像地址,保存
sudo gedit ~/.condarc
1
2
清华源镜像地址:
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
3.打开anaconda图形界面
方法1,终端键入:
source ~/anaconda3/bin/activate root
anaconda-navigator
1
2
方法2,终端键入:
conda install -c anaconda anaconda-navigator
anaconda-navigator
1
2
4.创建环境
在anaconda的environment里creat一个名字叫music的环境,点确定,等待完成
5.激活环境
source activate music
1
在这里插入图片描述
6.刚建立的music环境中,下载spleeter需要的环境
接着5继续终端键入:
git clone https://github.com/Deezer/spleeter
1
(若没有git就按照提示装一个)
继续键入:
conda install -c conda-forge spleeter
1
7.模型下载与解压(注意模型放的位置,仔细看下图和路径)
模型下载链接:
https://github.com/deezer/spleeter/releases
如果下载慢可以看我主页CSDN上传的文件
解压位置:
/home/ef/pretrained_models/2stems
测试音乐位置:
/home/ef/test.mp3
在这里插入图片描述
在这里插入图片描述
8.音乐分离的运行
终端键入运行:
spleeter separate -i test.mp3 -p spleeter:2stems -o output
1
在根目录可以看到output
在这里插入图片描述在这里插入图片描述
三、更精确的高质量模型:
模型下载链接:
https://github.com/deezer/spleeter/releases
分离2轨道
下载2stems-finetune.tar.gz,解压后只需替换原模型的5个文件即可,解压目录和运行代码均不变,windows和linux相同:
解压目录:pretrained_models/2stems
linux:
在这里插入图片描述windows:
在这里插入图片描述linux运行代码:
spleeter separate -i test.mp3 -p spleeter:2stems -o output
1
windows运行代码:
python -m spleeter separate -i D:/code/test.mp3 -p spleeter:2stems -o output
1
分离5轨道
下载5stems-finetune.tar.gz,解压到pretrained_models/5stems,并执行代码:
//linux下:
python -m spleeter separate -i D:/code/test.mp3 -p spleeter:5stems -o output
//windows下:
spleeter separate -i test.mp3 -p spleeter:5stems -o output
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/jc/110941.html