今天主要以百度的中文分词技术来讲解。通过对搜索引擎分词技术的了解,可以让大家做SEO的时候更合理的去书写SEO优化中的重点,三个标签的确定。
分词技术是中文搜索引擎特有的技术支持。中文信息和英文信息的差别在于;英文单词之间用的是空格分隔的,这对中文就行不通了,搜索引擎必须将整个句子切割成小单元词,如“我的兄弟姐妹”拆分出来的形态是我、的、兄弟、姐妹。分词技术的效率直接影响到整个系统的效率。
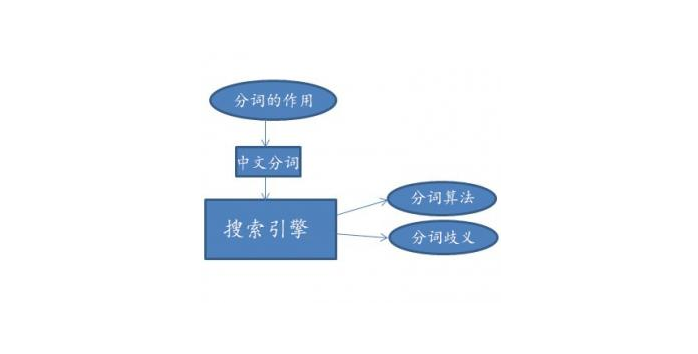
分词的方法基本上有两种:基于字符串匹配的分词方法和基于统计的分词方法:
1、基于字符串匹配的分词方法
按照匹配方向的不同,可分为正向匹配、逆向匹配和最少切词。可将这三种方法混合起来使用,即正向最大匹配、逆向最大匹配、正向最小匹配、逆向最小匹配。
正向最大匹配:假设字典中最长的词语数字为m,先根据汉语标点符号及特征词把汉语切分为短语,然后去取短语的前m个字,在字库里面查找是否存在这个词语,如果存在,短语就去掉这个词;如果不存在就去掉m这个字的最后一个字,接着检查剩下的词是否是单字,若是则输出此字并将此字从短语中去掉,若不是则继续判断字库中是否存在这个词,如此反复循环,直到输出一个词,此后继续取剩余短语的前m个字反复循环,这样就可以将一个短语分成词语的组合了。
以“我是一个好人”为例,假设字典中最长词语字数为3,正向最大匹配顺序为:
1、取出短语“我是一”,检查“我是一”是否在字典中存在或是一个单字,处理方式是去掉最后面的“一”字
2、检查短语“我是”是否在字典中存在或是一个单字,处理方式是去掉一个“是”字
3、检查“我”字是否在字典中存在字典中存在或是一个单字,“我”是一个单字,将“我”输出
4、继续取出短语“是一个”,检查“是一个”是否存在字典中存在或是一个单字,处理方式是去掉最后的“个”字
5、检查短语“是一”是否存在字典中存在或是一个单字,处理方式是去掉“一”字
6、检查“是”字是否存在字典中存在或是一个单字,“是”是一个单字,将“是”字输出
7、取出短语“一个好”,检查“一个好”是否在字典中存在或是一个单字,处理方式是去掉最后的”好“字
8、检查短语“一个”,发现是字典中一个词,直接输出。
9、检查短语“好人”,发现是字典中的一个词,直接输出
10、最后输出结果为:我、是、一个、好人。
逆向最大匹配:以句子结尾处进行分词的方法。逆向最大匹配技术最大的一个作用是用来消歧。如“富营销线下聚会在下城子镇举行”按照正向最大匹配结果为:富/营销/线/下/聚会/在/下城子镇/举行,很显然这当中产生了歧义。下城子镇是一个地名,没有被正确地切分。采用逆向最大匹配技术可以修正这个错误。例如设定一个分词节点大小为7,那么“在下城子镇举行”中很显然“举行”被分了出来,最后剩下“聚会在下城子镇”,这样一来歧义就消除了。
正向最小匹配/逆向最小匹配:一般很少使用到,实际使用中逆向匹配的精确度 高于正向匹配度。
基于统计分词方法:直接调用分词词典中的若干词进行匹配,同时也使用统计技术来识别一些新的词语,将所有的统计结果匹配起来发挥切词的最高效率。
分词词典是搜索引擎判断词语的依据,基本上收录了汉语词典当中所有的词语。如我们搜索引擎中输入“我要减肥了”,“减肥”两字就会被判定为一个词语,现在网络上经常会出现一些新造的网络流行语如:“神马”、“犀利哥”等,这样的词也都会慢慢地被收录。分词词典只有不断更新才能满足我们日常搜索判断的需求。
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/jc/116519.html