robots禁止网站抓取,还会被搜索引擎索引收录吗?
网站优化诊断的其中一项,就是检查有无做robots文件,是否规范。如果网站的robots协议文件禁止了搜索引擎蜘蛛,那么无论你怎么优化都不会被收录。
趁着写这篇文章,给这句话做个纠正,请大家认真阅读并且理解。如下:
如果你的网站添加了robots协议文件,并且设置了禁止搜索引擎蜘蛛的指令,那么你的网站内容将不会被抓取,但有可能会被收录(索引)。
有些人可能会有疑问,搜索引擎蜘蛛爬行url页面,页面需要有内容呈现出来反馈给到蜘蛛,才有可能会被收录。那么,如果内容都被禁止了还会被收录吗?这是什么意思呢?这个问题这里先不解释,大家先看看下面的图片吧。
如图所示,以上是site:淘宝域名出现被收录的结果。从site结果里面可以清楚的看到,从site结果里面可以清楚的看到,这里收录了很多淘宝网站的页面,显示收录结果为2亿6159万个页面。但是大家不知道有没有发现一个问题,这些页面抓取的描述内容都是提示了这样一段文字:由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述
robots禁止搜索引擎蜘蛛后为什么会被收录呢?
这里有个认知上的错误,也可能是惯性逻辑思维的错误思考。大家都认为蜘蛛不能抓取内容就不会收录,实际上爬行、抓取、索引(收录)是不同的概念。很多人学习SEO的时候,经常性的对一些SEO的概念混肴不清,导致在后面的SEO优化过程当中并不能发挥出很好的效果。
还是先来说说robots协议到底是在做什么?既然是协议,那肯定是双方同意、认可的规矩。这个甲乙自然就是网站和搜索引擎(或者说搜索引擎蜘蛛)之间的协议。robots文件会放在根目录下,蜘蛛进入网站会第一时间访问这个文件,然后看看协议里面有没有禁止了那些页面不能抓取,如果禁止了就不会再去抓取。
一个页面想要去搜索引擎索引(收录),收录要有蜘蛛爬行和抓取,既然不抓取,理所当然的就会被认为这个页面是不会被收录。这样的思维是错误的,不抓取也是可以被索引(收录)。如淘宝就是一个典型的案例,网站添加了禁止协议,最后还是被收录。原因在于,百度从其它渠道平台推荐的外部链接了解到这个网站,虽然被禁止抓取,但从标题和推荐链接的数据里还是可以判断出与该页面相应的内容信息。
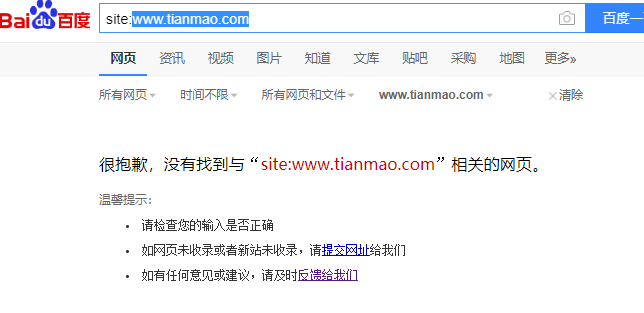
好了,关于robots的知识分享就和大家说到这里。可能有些人还有疑问,比如说:robots既然不能够阻止页面被收录,有没有办法禁止索引(收录)呢?当然有,大家可以site天猫,如图:
建议可以到百度学院了解robots使用简介:https://ziyuan.baidu.com/college/courseinfo?id=267&page=12#h2_article_title28
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/jc/117132.html