AI语音已逐步渗透到了大众的生活中,但是刻板的对话方式似乎还困扰着广大用户。
全双工这个概念对人工智能行业从业者来讲,并不陌生。谈到全双工,此前,谷歌Duplex帮助人们通过电话预约餐厅和理发师的功能,带来了有趣的观感体验,在I/O 2019上,谷歌宣布对Duplex进行重大扩展。

谷歌Duplex
在推进对话交互智能的市场化应用过程中,思必驰同样发现,自然流畅的对话体验、类人化的交互体验成为了绝对的刚需。
因此,具备以上两个特点的全双工语音交互技术,成为了关注的焦点。思必驰联合创始人、首席科学家俞凯,早在剑桥大学期间主导开发了全双工口语对话系统,2010年参加国际对话系统研究挑战赛时,获得可控测试的冠军,这也是世界上最早的全双工端到端口语对话系统之一。区别在于,与现在广泛作用于物联网智能终端设备的全双工交互系统相比,当时的主要应用,在基于电话信道的人机交互方面。
全双工是个系统工程
作为系统工程,全双工需要综合利用语音语言技术的各个模块,实现前后联动,例如,其对前端信号处理、AEC回声消除有强相关依赖,实时上传的音频对噪声处理、音频音质要求较高,同时,作为系统工程,全双工涉及到全链路语音交互的各个模块,其同样需要对识别后的识别信息、语义信息等进行综合判断及处理,并做出决策。

半双工&全双工
因此,全双工交互技术的提升涉及到对话系统的各个模块,不仅各个模块的功能需要提升,模块间的配合能力更需要完善。
思必驰在推进全双工交互技术的市场落地过程中,发现了一个更有效的事情,“全双工+语义拒识”让交互体验更加优化。全双工固然重要,但语义拒识算法,却往往容易被人忽视。
语义拒识算法
受限于语音技术的发展,现有的对话系统受噪声条件的影响非常明显,缺乏稳健性。在对话系统中,说话人的检测和基于语义的拒识是其非常重要的组成部分。当说话人的语音模糊不清或者语音数据不在已有训练集合中时,识别系统会产生识别错误,从而影响对话系统的识别和理解效果。
在半双工状态下,环境噪声以及周围人声容易引起无效输入,对话系统或错误响应,或给出“没听懂”的呆板播报,并且播报时不能打断,十分影响交互效率。全双工状态下,对无实际语义的输入则不会给出响应。
拒识算法主要目的是去除没有语义意义的音频片段,节省后端处理的计算资源,提高整个对话系统的交互鲁棒性,提升用户使用体验,避免错误的语义理解引发错误的反馈到用户端。
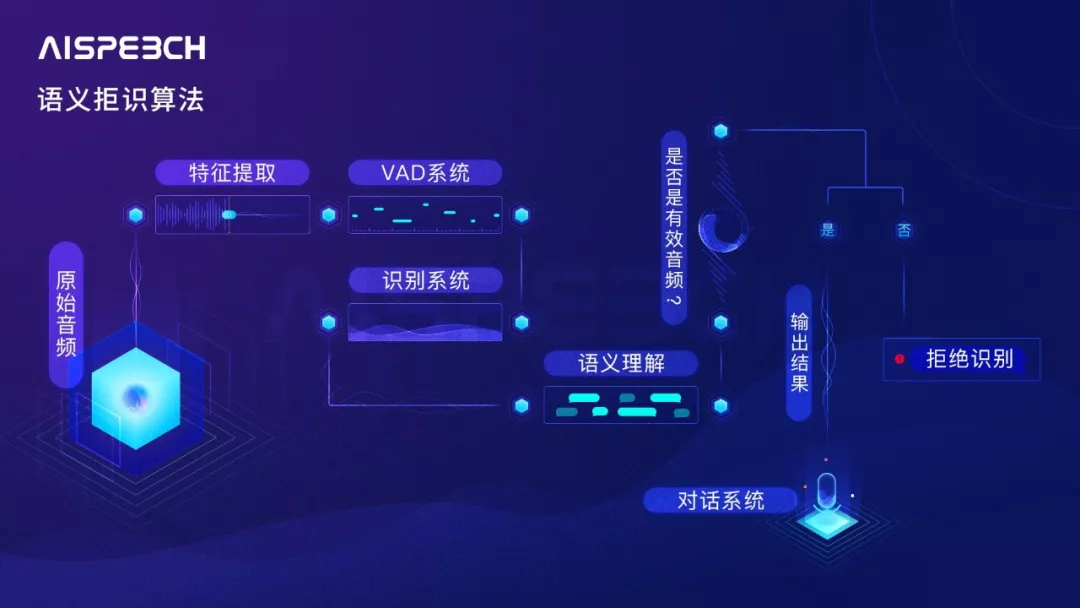
思必驰语义拒识算法
思必驰拒识算法能够解决的很多噪声和无语义意义的问题,例如用户无意义的嗯啊声、背景噪声与闲聊声、纯音乐声、声音幅度小、各种笑声尖叫声,无厘头声音等。
语义拒识对全双工对话交互而言至关重要,可以说,拒识做不好,全双工的效果往往也会差强人意。
思必驰全双工交互技术,更强的持续对话能力
思必驰全双工交互技术,让更流畅的多轮对话成为常态,说法更自由。
l连续交互免唤醒
过去,半双工状态下,用户的跨领域交互每次交互都需要重新唤醒,于是,免唤醒技术成为改善体验的焦点。近些年,免唤醒技术已不是新鲜方案,有的采用“便捷唤醒词定制”,有的采用“唤醒+识别理解一体化”方案,但都存在着诸如“漏字”这类一系列的风险:
“你好小驰明天天气如何?”
漏字通常出现在唤醒词和后面识别文本连接的地方,也就是句子中段。当系统在识别过程中漏掉“明”字时,就会造成时间信息不清晰(“明天”还是“今天”?),系统无法明确用户的真正时间指令。而现在,思必驰全双工技术方案可实现一次唤醒,在多个领域持续交互,跨领域指代消解。
l动态断句
在日常生活中,很多用户说话会出现拖音现象,说话过程中,有思考/间断的过程,因此会出现很多半截句,简单粗暴的调整语音端点检测阈值的做法往往会带来对话卡顿的现象。
半双工状态下,对话系统设定了固定的停顿检测时间,用户还未表达完整句子稍微一犹豫/停顿,会被语音端点检测系统误断句,造成输入内容不完整,机器无法理解。
思必驰全双工交互技术则在云端根据用户说话节奏和内容,忽略无意义噪声,动态断句,既能保证用户输入的完整性,又能保证较快的响应速度。在回复方面,则可以适时的回复“嗯”等接话话术,系统打破了对用户说话规则的要求,用户可以按照自身的说话习惯来进行交流,交互过程更加人性化。
l语义打断,避免误打断
在半双工状态下,语音合成播放时很难进行打断,在一些终端设备上,行业内普遍采用的打断方式是“快捷唤醒词打断”,说法十分固定,无法泛化,需要定制多个唤醒词,当用户想打断的时候,必须要重复唤醒词,容易发生误打断。同时,对话打断对环境有较高要求,在有噪声的时候,也容易被误打断。
思必驰全双工交互技术可在对话的过程中,实时语义打断,不容易出现误打断,同时,对没有语义的输入,则不会打断语音合成播放。
这一技术在智能客服的领域将会大大改善消费者的体验,消费者可以随时随刻打断机器人客服的无效对话信息,进行信息咨询。
如何判断什么时候接话,什么时候反问,机器需要有智能决策的能力,这也是思必驰全双工技术的一大特性:主动交互。根据用户表达状态,如“正常说话”、“主动沉默”、“无意义表达”等状态,来给予相应的主动反馈。
思必驰全双工交互技术支持智能判断,尤其是能够主动打断用户的复杂冗长表达,主动打破沉默僵局,实现流畅自然的用户口语交流习惯。当识别到用户正常表达时,机器等待说完后答复反馈;当用户大段无意义输入或表达过于复杂时,会主动打断并提示反问;在交互过程中,当用户沉默时,则可以主动发起对话交互。
同时,经过反复打磨和优化,该技术对系统功耗几乎无影响,实现低功耗下的最优质体验。

思必驰全双工语音交互
实践,是检验真理的唯一标准
目前,思必驰全双工交互技术已展开全线方案渗透,包括AIOT方案和企业信息智能服务,深入作用汽车、家居、电子、教育、医疗、政务、金融、物流、酒店等场景。以音箱方案为例,接入全双工系统后,这款“智能助理设备终端”将更似真人助理,更具备人类亲和力的特质和逻辑思维能力,整个对话体验更加自然流畅。

思必驰业务场景
云端全双工中控大脑持续优化
针对全双工交互技术,思必驰将持续优化云端全双工中控大脑,持续进行策略优化、场景优化、单点技术模块优化,将交互体验做的更好。
未来,多模态交互将会让全双工交互技术发挥更大的能量,配合声纹识别、图像处理、虹膜识别等技术,过滤无用信息,人机交互会变得更加贴合人性,或许不远的未来,你甚至分不清与你隔屏对话的,到底是人还是机器人。
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/zixun/764.html